Apa itu Web Mining¶
Web mining digunakan untuk menemukan informasi yang berguna atau pengetahuan dari web hyperlink structure, page content dan usage data. Walaupun web mining menggunakan teknik data mining seperti yang telah disebutkan tetapi tidak murni seluruhnya karena heterogen dan semi terstruktur dan tidak terstrukturnya data web. Berdasarkan tugas pokok yang dilakukan dalam proses menambang, web mining dapat kelompokkan menjadi tiga bentuk, yaitu Web Structure Mining, Web Content Mining, dan Web Usage Mining
-
Web struktur Mining : Web structure mining adalah tugas untuk menemukan pengetahuan yang bermanfaat dari hyperlink (atau link singkatnya), yang menyatakan struktur dari dari web. Misalkan dari link-link kita dapat menemukan web page penting, yang menjadi teknologi utama yang digunakan dalam mesin pencarian. Kita dapat juga menemukan komunitas dalam media sosial. Datamining biasa tidak melakukan tugas tersebut, karena tidak ada struktur link dalam tabel tradisional.
-
Web Content Mining. Web content mining adalah mengektrak atau menambang informasi yang berguna atau pengetahuan dari isi halam web. Misalkan kita dapat secara otomatis mengklasifikasikan dan mengelompokkan halam wen sesuai deng topiknya. Tugas ini sama dengan data mining biasa. Akan tetapi kita juga dapat menemukan pla dalam web site untuk mengektrak data yang berguna seperti deskripsi produk, postingan forum, dan lain sebagainya untuk banyak tujuan. Selanjutnya kita dapa menambang ulasan dan postingan dari forum untuk menemukan opini konsumen. Disin tidak ada pada data mining tradisional.
Contoh sederhana dari web content mining adalah :
-
**Analisa Sentimen terhadap review produk ** Analisa Sentimen dapat dilakukan terhadap ulasan ulasan dari produk produk Amazon yang di-scrap. Suatu penelitian membantu mengidentifikasi emosi pengguna terhadap produk tertentu. INi dapat membantu penjual dan calon pembeli lain yang tertarik membeli dalam memahami penilaian secara umu terhadap suatu produk tertentu.
-
Mengoptimalkan penjualan dropshipping
Dropshipping adalah bentuk bisnis yang memungkinkan perusahaan tertentu untuk bekerja tanpa inventory atau depository untuk menyimpan produknya. Anda dapat menggunakan web web scraping untuk mendapatkan harga produk opini user dan pemahaman terhadap kebutuhan konsumen, dan mengikuti arah perkembangan produk.
-
Monitoring reputasi e-commerce Dengan adanya web mining dapat membantu mengektraksi review data sehingga dapat menjadi masukan untuk mengukur sentiman pengguna/nasabah terhadap suatu organisasi
-
Web Usage Mining. Web Usage Mining adalah menemukan pola akses user dari log web yang disimpan, yang merekam setiap klik yang dilakukan oleh setiap user. Web Usage Mining menggunakan banyak algoritma algoritma datamiing. Salah satu masalah utama dalam Web Usage Mining adalah preprocessing dari data clikstream dalam data usage log agar menghasilkan data yang benar untuk ditambang.
Dalam kuliah ini kita lebih menekannkan pada dua tugas yaitu web content mining dan web struktur mining.
Apa itu web scraping¶
Web scraping adalah proses mengektrak data dari website. Selanjutnya data yang tersedia di website dinyatakan dalam bentuk format yang dapat dengan mudah dioleh oleh mesin untuk dianalisa lebih lanjut. Misalkan data dinyatakan dalam bentuk format CSV, disimpan dalam database tertentu dan sebagainya. Data yang ada di website itu bentuknya tidak terstrukur, artinya tidak siap digunakan untuk analisis.
Ada beberapa cara scrape data dari website untuk diektrak informasinya untuk digunakan. Bentuk yang paling sederhana, adalah dengan menyalin dan mempast bagian bagian tersebut dari website. TEntunya ini tidak praktis dilakukan jika banyak data yang yang akan diektrak, atau tersebar dibeberapa website. Sehingga diperlukan tool khusus dan teknik khusus yang digunakan untuk melakukan secara otomatis proses ini, dengan menetapkan webiste yang akan dijelajahi informasi apa yang akan dicari dan apakah ektraksi data berhenti diakhir halama yang ditemukan ataukah mengikuti hyperlink dan mengulangi proses secara rekursif. Proses automatis dari web scraping juga memungkinkan untuk dilakukan apakah proses akan dijalankan pada rentang waktu tertentu dan menangkap perubahan yang terjadi dari data.
Teknik Webscraping membutuhkan pemahaman teknologi yang digunakan untuk menampilkan inforamasi pada web. Oleh karena itu diperlukan pemahaman tentang HTML dan Document Object Model (DOM) termasuk pemahana sintak XPath untuk memilih elemen pada website
untuk Apa web scraping diperlukan¶
-
Untuk web indexing yang digunakan oleh mesin pencari misal Google untuk menganalisa secara masal web untuk membangun indeknya.
-
Memonitoring perubahan data e-commerse secara online untuk tujuan pemasaran.
Seandainya kita telah memiliki toko penjualan sepatu dan ingin untuk melacak terus harga pesaing kita. Kita dapat mengunjungi website pesaing kita setiap hari untuk membandingkan dengan masing masing harga sepatu yang kita miliki. Akan tetapi ini akan butuh waktu banyak dan tidak layak dilakukan jika kita menjual ribuan sepatu atau dibutuhkan untuk mengecek perubahan harga lebih sering. Ini adalah pekerjaan yang tidak efisien dan efektif . Oleh karena itu kita perlu mesin atomatis dengan teknik web scraping untuk menggantikan proses manual tersebut
- Web scraping juga banyak digunakan oleh is also increasingly being used by scholars to create data sets for text mining projects; these might be collections of journal articles or digitised texts. The practice of data journalism, in particular, relies on the ability of investigative journalists to harvest data that is not always presented or published in a form that allows analysis.
Apakah web scraping legal?¶
Jika data yang ditarik (scrap) keperluan sendiri, dalam prakteknya tidak masalah. Akan tetapi jika data akan dipublikasikan lagi maka ada beberapa aspek hukum yang harus dipertimbangkan.
Secara singkat bahwa legalitas tidaknya kita melakukan web scraping atau abu abunya tergantung pada tiga hal ini:
- Bentuk data yang akan discrap
- Bagaiman anda merencanakan untuk menggunakan data yang di-scrap
- Bagaiman anda mengektrak data dari website
Nomor 1 dan 2 sangat jelas sehingga kita akan memulainya daru sini sebelum membahas nomor 3.
Apa saja dari bentuk data yang ilegal untuk di scrap¶
Data seperi e-commerce, personal atau data article , adalah bentuk data yang sangat terkait dengan legalitas. Dua bentuk data yang kita perlu hati-hati atau dikwatirkan legalitasnya adalah
- Personal Data
- Copyrighted Data
JIka data yang anda tarik adalah bukan bentuk data dari diatas, secara umum adalah legal
Bentuk data 1: Personal Data¶
Personal data adalah data yang digunakan secara langsung atau tidak langsung untuk mengidentifksi individu tertentu.
Bentuk dari data personal yaitu :
- Name
- Phone Number
- Address
- User Name
- IP Address
- Date of Birth
- Employment Info
- Bank or Credit Card Info
- Medical Data
- Biometric Data
Bentuk data #2: Copyrighted Data¶
Bentuk data yang perlu hati hati untuk ditarik adalah copyrighted data.
Copyrighted data data yang dimiliki oleh pribadi atau bisnis untuk mengendalikan terkait reproduksi dan kepemilikan. Seperti gambar dan lagu walaupun data dipublikasi di internet bukan berarti itu legal untuk ditarik tanpa pemberitahuan pemiliknya.
Secara umum data tersebut adalah:
- Articles
- Videos
- Pictures
- Stories
- Music
- Databases
Mengekstrak data berhak cipta bukanlah tindakan ilegal, jadi tindakan legal dan ilegal benar-benar tergantung pada bagaimana Anda berencana menggunakan data hak cipta tersebut setelah Anda menyalin /men-scrap data tersebut. Juga aspek database data, artinya jika menarik seluruh database dari web dan kemudian merepoduksi ulang untuk tujuan sendiri. Amerika dan EU memiliki regulasi yang berbeda terkait aspek ini.
Membangun Scraping Website .¶
Untuk melakukan tahapan penarikan data dari suatu halaman halaman web maka yang perlu dipehatikan adalah
- Menganalisa strutktur HTML dari laman web. Scraping adalah tentang menemukan pola dalam laman- laman web dan mengektraksi isi dari laman tersebut. Sebelum mulai untuk menulis tool scrapyng (scraper), kita perlu untuk memahami struktur HTML dari web page yang akan ditarik datanya dan mengidentifikasi pola didalamnya. Pola dapat terkait dengan penggunaan classes, id, and elemen elemen lain HTML
- Membuat Scrapy parser dengan python. Setelah menganlisa struktur dari halaman web yang akan ditarik datanya, kita lakukan implementasi dengan menulis code untuk menghasilkan scrapy parser . Scrapy parser bertanggung jawab untuk menjelajahi web yang akan ditarik datanya dan mengektrak informasi sesuai dengan aturan yang dibuat
- Mengumpulkan dan menyimpan informasi Parser dapat menyimpan hasilnya sesuai dengan format yang anda inginkan misalkan csv atau json. Ini adalah hasil akhir dari data yang telah dikumpulkan
1.Analisa Struktur HTML Halaman Website¶
XPath (kepanjangan dari XML Path Language) adalah expression language yang digunakan untuk menetapkanbagian bagian bagian bagian dari dokumen XML . XPath digunakan dalam perangkat lunak dan bahasa yang digunakan untuk manipulasi dokumen XML, seperti XSLT, XQuery atau alat alat web scraping XPath dapat juga digunakan dalam struktur yang sama seperti XML, misalkan html
Markup Languages¶
XML dan HTML adalah markup languages. Artinya keduanya menggunakan sekumpulan tags atau rule untuk menyusun dan menyedian informasi yang ada didalamnya. Struktur ini membantu untuk secara otomatis untuk pemrosesan , pengeditan, pemformatan dan penampilan dan pencetakan informasi tersebut.
Dokumen XML menyimpan data dalam format plain teks. Ini menyediakan perangkat lunan dan perangkat kerans dengan cara bebas untuk menyimpan, mentransformasi, dan menshare data. Format XML adalah format terbuka. Anda dapat membuka dokumen XML dalam editor teks dan data yang ada didalamnya dapat disajikan. Ini memungkinkan pertukran sistem yang tidak kompatibel dan mudah untuk mengkonversi suatu data.
Dokumen XML memilki aturan-aturan dasar sebagai berikut:
- Dokumen XML disusun menggunakan nodes, yaitu terdiri dari node node elemen, node node atribute dan node node teks
- Node node elemen XML harus harus dibuka dan ditutup tag, misal. tag pembuka
<catfood>dan tag penutup</catfood> - Tag XML adalah sensitif e, misal.
<catfood>tidak sama dengan<catFood> - Elemen XML harus bertingkat dengan benar:
<catfood>
<manufacturer>Purina</manufacturer>
<address> 12 Cat Way, Boise, Idaho, 21341</address>
<date>2019-10-01</date>
</catfood>
- Node node teks (data) isinya didalam tag pembuka dan tag penutup
- Node note atribut XML berisi nilai-nilai yang harus di quoted, misal.
<catfood type="basic"></catfood>
XPath selalu mengasumsikan data terstruktur (structured data).¶
Now let’s start using XPath.
Menelusuri pohon node HTML menggunakan XPath¶
Cara yang paling umum untuk merepresentasikan struktur dari dokumen XML atau HTML adalah dengan pohon node (node tree):
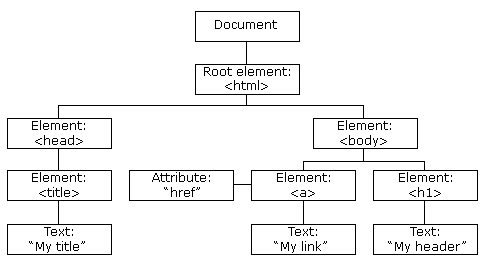
Dalam sebuah dokumen HTML , segala sesuatunya adalah node:
- Seluruh dokumen adalah node dokumen
- Setiap elemen elemen HTML adalah node elemen
- Teks didalam elemen HTML adalah node-node teks
Node-node dalam suatu pohon memiliki hubungan hirarki dengan yang lain. Kita menggunakan istilah parent, child dan sibling untuk menjelaskan hubungan ini:
- Dalam pohon node, node paling atas disebut dengan root (atau root node)
- Setiap node memiliki tetap satu parent, kecuali root (yang tidak memiliki parent)
- Sutau node dapat memilik satu, beberapa atau tidak sama sekali children
- *Sibling adalah node-node dengan parent sama
- Serangkaian hubungan antra node ke node disebut dengan path
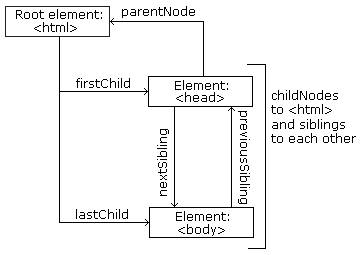
Path-path dalam XPath didefinisikan dengan menggunakan slash (/) untuk memisahkan langkah/tahapan dalam rangkaian keterkaitan node, seperti URL-URLS atau direktori Unix
Dalam XPath, semua ekspresi didasarkan pada context node. Context node adalah node path dari mana dimulai. Default context adalah node root , yang dinyatakan dengan slash tunggal (/), seperti dalam contoh diatas.
Yang paling banyak digunakan untuk ekpresi patha adalah sebagai berikut:
| Expression | Description |
|---|---|
nodename | Memilih semua node dengan nama “nodename” |
/ | Garis miring tunggal awal menunjukkan pemilihan dari simpul akar, garis miring berikutnya menunjukkan pemilihan simpul anak dari simpul saat ini |
// | Pilih node anak langsung dan tidak langsung dalam dokumen dari node saat ini - ini memberi kita kemampuan untuk "skip levels" |
. | Piiih context node saat ini |
.. | Pilih parent dari context node |
@ | Pilih atribut dari context node |
[@attribute = 'value'] | Pilihan node dengan nilai atribut tertentu |
text() | Pilih isi teks dari node |
| | | Rantai ekspresi dan membawa kembali hasil dari ekspresi mana pun |
Sintaks XPath lanjutan¶
Operators¶
Operator digunakan untuk membandingkan node-node. Terdaoat operator matematika,operator boolean. Operators dapat memberikan nilai boolean (benar /salah) sebagai hasil. Disini beberap yang banyak digunakan :
| Operator | Penjelasan |
|---|---|
= | Membandingkan kesamaan, dapat digunakan untuk nilai numerik maupun teks |
!= | Dignuanak untuk membandikanketidak samaan |
>, >= | Lebih besar, lebih besar dari atau sama dengan |
<, <= | Lebih dari, lebih dari atau sama dengan |
or | Boolean atau (or) |
and | Boolean dan (and) |
not | Boolean bukan (not) |
Contoh¶
| Ekspresi Path | Hasil Ekspresi |
|---|---|
| html/body/div/h3/@id=’exercises-2’ | Apakah exercise 2 ada? |
| html/body/div/h3/@id!=’exercises-4’ | Apakah exercise 4 tidak ada? |
| //h1/@id=’references’ or @id=’introduction’ | Apakah terdapat terdapat references h1 atau introduction? |
Predikat¶
Predikat digunakan untuk menemukan node tertentu atau node yang berisi nilai tertentu
Predikat selalu diletakkan dalam kurung siku, dimaksudkan untuk memberikan informasi pemfilteran tambahan untuk mengembalikan node. Anda dapat memfilter pada sebuah node dengan menggunakan operator atau fungsi
Examples¶
| Operator | Explanation |
|---|---|
[1] | Pilih node pertama |
[last()] | Pilih node yang terakhir |
[last()-1] | Pilih node terakhir kedua |
[position()<3] | Pilih dua node pertama, perhatikan posisi pertama dimulai dari 1, bukan = |
[@lang] | Pilih node yang memiliki atribut ‘lang’ |
[@lang='en'] | Pilih semua node yang memiliki atribute dengan nilai atribute “en” |
[price>15.00] | Pilih semua node yang memiliki node price yang lebih besar dari 15.00 |
Pencarian dalam teks¶
XPath dapat melakukan pencarian dalam teks mengunakan fungsi. Perhatikan: pencarian dalatem teks adalah case-sensitive!
| Path Expression | Result |
|---|---|
//author[contains(.,"Matt")] | Cocokkan pada semua node author, dalam node sekarang yang berisi Matt (case-sensitive) |
//author[starts-with(.,"G")] | Cocokkan pada semua node author, dalam node sekarang yang dimulai dengan G (case-sensitive) |
//author[ends-with(.,"w")] | Cocokkan pada semua dalam node sekarang yang yang berakhiran dengan w (case-sensitive) |
Menampilkan source dari suatu page¶
Untuk menemukan xpath element halaman website maka kita dapat membuka source page halama tersebut. Yaitu dengan cara klik kanan pada halaman

Memetakan suatu webpage denganXPath menggunakan console suatu browser¶
KIta akan menggunakan kode HTML yang ada pada website portal tugas akhir mahasiswa sebagai contoh. Biasanya, setiap browser web dapat menampilkan sumber kode HTML dengan fungsinya tersendiri dari browser tersebut. Contoh diatas adalah menggunakan browser firefox dengan melakukan klik kanan pada pointer akan menampilakn submenu salah satunya View Page Source. Kemudian klik menu tersebut akand dapatkan source sumbernya sebagai berikut.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>Portal Tugas Akhir Univ. Trunojoyo</title>
<link rel="stylesheet" href="https://pta.trunojoyo.ac.id/css/reset.css" type="text/css"/>
<link rel="stylesheet" href="https://pta.trunojoyo.ac.id/css/style.css" type="text/css"/>
<link rel="stylesheet" href="https://pta.trunojoyo.ac.id/css/960_12_col.css" type="text/css"/>
<link rel="stylesheet" media="screen" href="https://pta.trunojoyo.ac.id/css/smoothness/jquery-ui-1.8.18.custom.css" />
<!--[if lte IE 8]> <link rel="stylesheet" type="text/css" href="css/ie.css" /> <![endif]-->
<!-- favicon -->
<link rel="shortcut icon" type="image/x-icon" href="https://pta.trunojoyo.ac.id/images/favicon.ico"/>
(...)
</body>
</html>
Kita dapat melihat dari source code bahwa judul dari halama ini dalam elemen title yang ada dalam elemen head , yang ada didalam elemen html yang berisi seluruh isi dari page
Sehingga jika kita ingin memberi tahu web scraper untuk mencari judul dari halaman ini, kita menggunakan informasi ini untuk menentukan path yang diperlukan untuk menjelajahi isi HTML dari page untuk menemukan element title . XPath memungkinkan untuk melakukan hal tersebut.
Kita dapat menjalankan query XPath langsung pada browser dengan JavaScript console yang ada didalamnya.
Menampilkan console dalam browser¶
- Pad Firefox, gunakan menut Tools > Web Developer > Web Console .
- PadaChrome, gunakan menut View > Developer > JavaScript Console
Disini bagaimana console tampak dalam browser Firefox :

Untuk saat ini, jangan khawatir terlalu banyak pesan error manakalan anda meliha dalam console ketika anda membukanya. Console akan dengan muncul prompt dengan karakter > (atau >> dalam Firefox) menunggu anda untuk mengetik perintah .
Sintaks untuk menjalankan query XPath dalam JavaScript console adalah $x("XPATH_QUERY"), misalkan:
$x("/html/head/title/text()")
Ini akan menghasilkan sesuatu seperti ini

<- Array [ #text "Portal Tugas Akhir Univ. Trunojoyo" ]
Menggunkan extension firefox xPath Finder¶
Untuk menentukan xpath dari element dari halam website dengan mudah dilakukan menggunakan xPath Finder. Jika belum ada ektension firefox xPath Finder ,silahkan install dulu extension tersebut. Penggunaannya adalah dengan cara klik pada icon extension curson akan berubah menjadi crosshair, kemudian pilih elemen yang diinginkan dengan kursor diarahkan pada elemen tersebut ( elemen akan berubah warna ). Klik elemen tersebut sehingga akan tampil xPath dari elemen tersebut di bawah kiri dari halaman

In [3]: fetch('https://pta.trunojoyo.ac.id/')
2020-09-25 04:32:42 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://pta.t
runojoyo.ac.id/> (referer: None)
In [4]: response.xpath("/html/body/div[2]/div[1]/div[2]/ul/li[1]/div[1]/a")
Out[4]: [<Selector xpath='/html/body/div[2]/div[1]/div[2]/ul/li[1]/div[1]/a' dat
a='<a class="title" href="#">Analisis Wa...'>]
Dari hasil scrap diatas ddapat diperbaiki ouputnya dengan perintah sebagai berikut
In [5]: response.xpath("//item/title/text()").extract_first()
In [6]: response.xpath("/html/body/div[2]/div[1]/div[2]/ul/li[1]/div[1]/a/text(
...: )").extract_first()
Out[6]: 'Analisis Wacana Media Online Detik.com dalam Memberitakan Peristiwa Ker
usuhan Mahasiswa Papua di Surabaya'
Mari kita bahas query XPath yang digunakan pada contoh diatas dengan XPath /html/head/title/text(). Yang pertama / menyatakan root dari suatu dokumen. Dengan query tersebut , kita memberit tahu browser untuk
/ | Start at the root of the document… |
|---|---|
html/ | … mengarahkan ke node html … |
head/ | … kemudaian ke node head yang ada didalamnya… |
title/ | … kemudaian ke node title yang ada didalamnya… |
text() | dan pilih node text yang terdapat dalam elemen itu |
Dengan menggunakan sintaks ini , XPath kemudian memungkinkan kita untuk menentukan path yang tepat pada suatu node.
Memilih judul tugas akhir¶

$x("/html/body/div[2]/div[1]/div[2]/ul/li[1]/div[1]/a")
Menggunakan Scraper Chrome extension untuk menavigasi XPath¶
Ini adalah alat yang memudahkan untuk mengimplementasikan XPath. Alat ini adalah tambahan dari browser Chrome untuk melakukan scrap data dari suatu website. Jika kita ingin menggunakan tool ini maka perlu ditambahkan pada browser Chrome kita seperti biasa kita menambahkan extension Chrome secara umum. Setelah kita install extension ini misalkan kita sedang menjelajahi pta.trunojoyo.ac.id, pada saat klik kanan pada website tersebut maka akan muncul menu

Dan bila kita mengklik menu scraper similar maka akan memunculkan XPath : //div[2]/div[1]/div[2]/ul/li dengan data yang ditarik dari halam website tersebut. Pada view di samping Xpath judul, penulis, dosen pembimbing dan abstrak ditampilkan dalam satu kolom dengan nama kolom text.

Untuk memperbaiki hasil tampilan ini, supaya menjadi field field yang sesuai, maka diperlukan perubahan dengan menambahkan nama kolom (field) dan memecah XPath yang sesuai. Berikut perubahan yang telah dilakukan

2.**Membuat Scrapy parser dengan Python ** (TUGAS)¶
Persiapan¶
instalasi alat alat yaitu
- Scrapy library
pip install scrapy
Desain secara umum scraping website¶
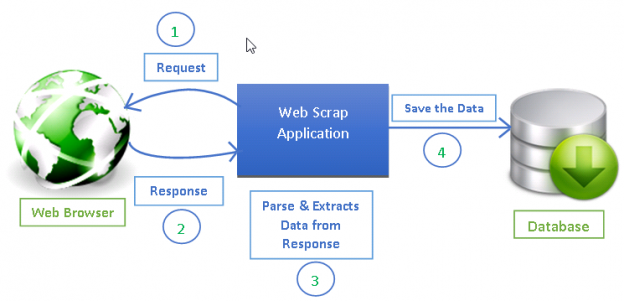
Pembuatan Proyek¶
Proyek 1. Menarik data dari website
a. Membuat proyek bernama mytugaswebmining
scrapy startproject mytugaswebmining
Akan terbentuk struktur folder mytugaswebmining seperti berikut
\---mytugaswebmining
| scrapy.cfg
|
\---mytugaswebmining
| items.py
| middlewares.py
| pipelines.py
| settings.py
| __init__.py
|
\---spiders
__init__.py
Scrapy merupakan framewerok aplikasi yang memungkinkan suatu suatu proyek sesuai dengan gaya pemrograman Object Oriented untuk mendefinisikan item-item dan spider untuk keseluruhan aplikasi. Struktur proyek dari scrapy yang telah dibuat diatas dengan masing masing sebagai berikut
- scrapy.cfg : ini adalah file konfigurasi proyek yang berisi modul pengaturan untuk proyek dan juga dengan informasi pengimplementasiannya.
- test_project : Ini adalah direktori aplikasi dengan banyak macam file yang benar bena bertanggung jawab untuk menjalankan dan menarik data dari urls-url web.
- items.py : item-item yang akan ditarik oleh scraper, ini juga bekerja seperti Python dicts. Karena kita dapat menggunakan plain Python dicts dengan Scrapy, Items menyediakan proteksi tambahan terhadap field-field yang tidak dideklarasikan. Hal itu dideklarasikan dengan pembuatan scrapy.Item class dan mendefinisika atribut atributnya sebagai scrapy.Field .
- pipelines.py : Setelah item di scrap oleh spider, item itu dikirim ke Item Pipeline yang memprosesnya dengan menggunakan beberapa komponen yang dijalankan secara berurutan. Masing masing item pipeline component adalah kelas Python yang harus mengimplementasikan metode yang disebut dengan process_item untuk memproses item yang di-scrap. Proses dilakukan terhadap item dengan memutuskan item harus diteruskan atau didrop dan tidak dinajutkan proses berikutnya.
- settings.py : Ini memungkinkan kita untuk mengkustom semua karakteristi komponen-komponen Scrapy termasuk core, extensions, pipelines dan spiders itu sediri.
- spiders : Spiders adalah direktori yang berisi semua spiders/crawlers seperti kelas-kelas Python . Ketika kita menjalankan atau meng-crawler spider maka scrapy mencari didalam di direktori ini dan mencoba untuk menemukan spider dengan namanya yang telah ditetapkan oleh pengguna. Spider mendefinisikan bagaimana site tertentu atau sekumpulan site, termasuk bagaimana melakukan crawl dan bagaimana mengektrak data dari page-pagenya. Artinya, Spiders adalah tempat dimana kita mendefinisikan tiga atribut utam yaitu start_urls yang meberi tahu URLs mana yang akan ditarik, , allowed_domains yaitu mendefinisikan domain mana saja yang boleh parse adalah suatu metode yang dipanggil ketika ada respon yang berasal dari lodged requests. Atribut ini adalah penting karena ini inti dari definisi Spider
Referensi¶
-
Zaki, Mohammed J., and Wagner Meira. Data mining and analysis: fundamental concepts and algorithms. Cambridge University Press, 2014 ↩
-
https://blog.datahut.co/scraping-amazon-reviews-python-scrapy/ ↩